EDA
Performed explorative data analysis using Top2Vec, a topical modelling algorithm to verify usefulness of text information in review dataset.
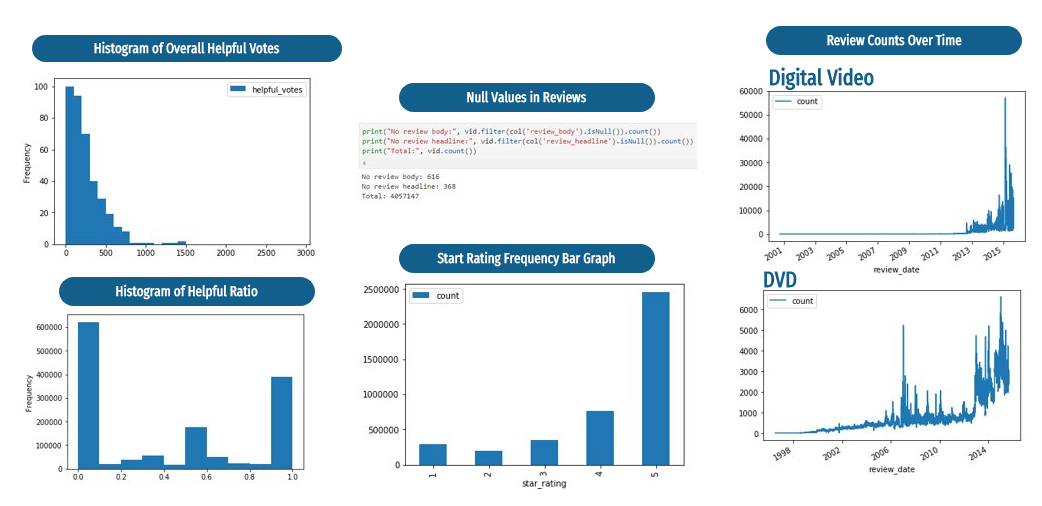
Initial General EDA
Top2Vec
Intention of running topical modelling on review column of dataset is to check whether it holds sufficient information for us to move forward with our project, and the breadth and depth of information in reviews is hard to capture manually given large dataset.
Import Spark NLP and import Top2Vec
#Spark NLP
import sparknlp
from sparknlp.pretrained import PretrainedPipeline
from sparknlp.annotator import *
from sparknlp.base import *
from pyspark.sql import SparkSession
from pyspark.sql.functions import *
import pyspark.sql.functions as F
#Top2Vec
from top2vec import Top2Vec
Initialize Spark NLP context
# Initialize spark context
spark = SparkSession.builder \
.appName("Spark NLP")\
.master("local[4]")\
.config("spark.driver.memory","16G")\
.config("spark.driver.maxResultSize", "0") \
.config("spark.kryoserializer.buffer.max", "2000M")\
.config("spark.jars.packages", "com.johnsnowlabs.nlp:spark-nlp_2.12:3.4.1")\
.getOrCreate()
Read the dataset with spark
# Read data
df = spark.read \
.option("quote", "\"") \
.option("escape", "\"") \
.option("ignoreLeadingWhiteSpace",True) \
.csv("dataset.csv",inferSchema=True,header=True, sep = ',')
Create a NLP pipeline that cleans the review_text, removing html tags and unnecessary words
documentAssembler = DocumentAssembler() \
.setInputCol('review_text') \
.setOutputCol('document')
cleanUpPatterns = ["<[^>]*>"]
documentNormalizer = DocumentNormalizer() \
.setInputCols("document") \
.setOutputCol("normalizedDocument") \
.setAction("clean") \
.setPatterns(cleanUpPatterns) \
.setReplacement(" ") \
.setPolicy("pretty_all") \
.setLowercase(True)
sentenceDetector = SentenceDetector() \
.setInputCols(["normalizedDocument"]) \
.setOutputCol("sentence")
tokenizer = RegexTokenizer() \
.setInputCols(['sentence']) \
.setOutputCol('token') \
.setPattern("\\W") \
.setToLowercase(True)
stopwords_cleaner = StopWordsCleaner()\
.setInputCols(['token']) \
.setOutputCol('clean') \
.setCaseSensitive(False)
finisher = Finisher() \
.setInputCols(["clean"]) \
docPatternRemoverPipeline = \
Pipeline() \
.setStages([
documentAssembler,
documentNormalizer,
sentenceDetector,
tokenizer,
stopwords_cleaner,
finisher])
ds = docPatternRemoverPipeline.fit(df).transform(df)
Transform cleaned dataset into Top2Vec input format
#Convert finished_clean column into string from array<string>
ds2 = ds.withColumn('finished_clean', concat_ws(',', 'finished_clean'))
#Remove comma from flattened string finished_clean
ds2 = ds2.withColumn("finished_clean", F.regexp_replace('finished_clean',r'[,]',' '))
#Final clean review data
ds2 = ds2.select('finished_clean')
#FlatMap to put it into Top2Vec model
review_text=ds2.rdd.flatMap(lambda x: x).collect()
Universal Sentence Encoder is used for Top2Vec
Bert is also an option, but I chose USE because it is one of the latest powerful Spark NLP transformer.
#Top2Vec powered by universal-sentence-encoder is going to analyze preprocessed review_text data and cluster them into topics with keywords
model=Top2Vec(documents=review_text, embedding_model='universal-sentence-encoder')
#Print total number of topics
model.get_num_topics()
#Extract necessary information from the trained model
topic_words, word_scores, topic_nums = model.get_topics(191)
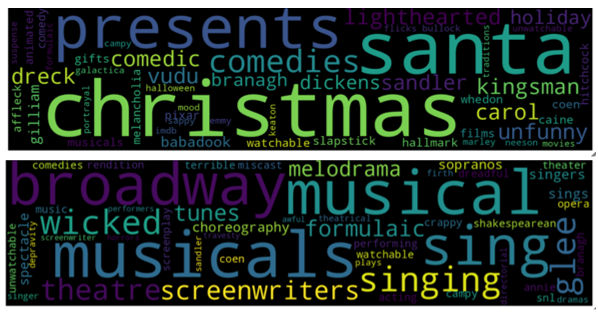
#Print out topic wordclouds
for topic in topic_nums[1:30]:
model.generate_topic_wordcloud(topic, background_color="black")
Insights
I could get 191 clearly defined and differentiated topic clusters from running Top2Vec on digital video category dataset, which indicates that the review text holds meaningful information.
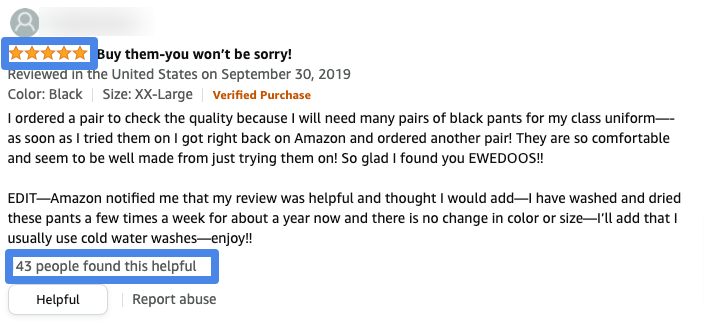
Star Ratings & Helpful Votes Defined
Amazon as of today
Star ratings & helpful votes significantly contribute to making top reviews, and most customers rely on reviews to purchase products. There can be many reasons why review is helpful. Sellers might have hard time figuring out what reviews are helpful but it is essential to increase sales. Hence, build an NLP model to classify reviews into helpful(1) or not(0) based on given information: star ratings, review text