Models
Models
- Our goal is to predict the sale price of a used car, which is a supervised regression problem. We pick our models base on two considerations, flexibility (accuracy) and interpretability.
- We value model accuracy over interpretability because:
- The industry we are in doesn’t require we provide explanation for the decision we make.
- Features of our used car dataset are easy to understand, thus making it easy for us to debug the model even without high model interpretability.
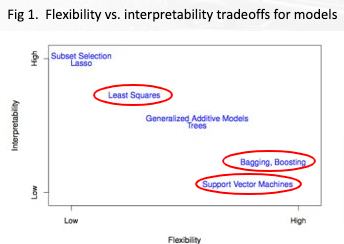
Our Model Selection
Linear Regression
Support Vector Regression with linear kernel
Decision Trees Ensemble method
Bagging Trees (Random Forest)
Boosting Trees
Initial Model Selection:
- Linear Regression is not flexible enough to capture all the variance of the model
- SVR would be very slow to train. (SVR training time scale badly with large number of training sample)
- Ensemble Trees would be the best method as it is flexible and has decent interpretability
Our Approach
- Train and tune all the models and compare the models’ accuracy
- Select the model with the best metric scores
Our Metrics
- R squared: the proportion of the variance explained by the model
- Root Mean Squared Error
- Mean Absolute Proportional Error