Data Preparation
Among all datasets, tweet's text needed heavier cleanup.
Data Cleanup
- Remove NaN
- Remove Emojis from tweets
- REGEX to clean tweet text
REGEX: Tweet text data includes emoji, hashtag, numbers, links and etc so REGEX is used to clean up each text
NLTK: NLTK tokenizing by word was used to extract more meaningful and logical words from cleaned tweet texts
Clustering On Location Data From Tweets
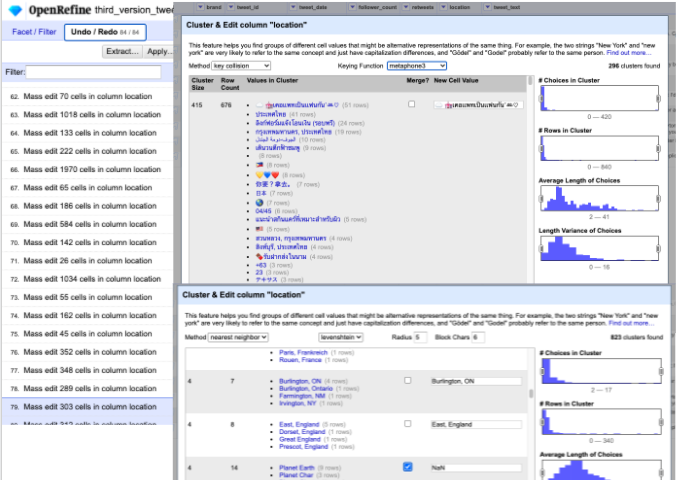
- Key Collision Methods
- Nearest Neighbor Methods
- Fingerprinting
- N-Gram Fingerprint
- Phonetic Fingerprint (metaphone3 was the most effective in finding and clustering data that was not appropriate as location)
For data that was not classified as location, “ ” was assigned.