Data Profile
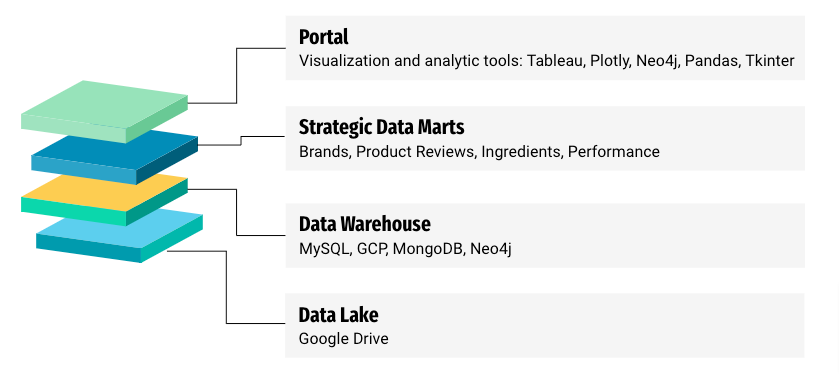
Data Infrastructure
Data Profile
| SOURCE | DESCRIPTION | DATA SIZE | FORMAT | |
|---|---|---|---|---|
| Product | Kaggle | Products listed on Sephora | 12.4MB | csv |
| Brands | Phantom Buster | Information on cosmetic brands and company information | 226KB | json/csv |
| Reviews | BazaarVoice API | User product reviews on Sephora | 500MB | json |
| Tweepy API | Users’ tweets with hashtag of brand name | 7.3MB | csv | |
| Ingredient | California Safe Cosmetics Program Product DB | Chemicals used in cosmetics that are known to be harmful | 2.2MB | csv |
Data Quality Dimensions Assessment
| Completeness | Accuracy | Consistency | Validity | Uniqueness | Integrity |
|---|---|---|---|---|---|
| Original data did not contain all products up to this year and tweets data was limited to recent data | Tweet data contained inaccurate feedback on brands as search query was simply limited to “#brand” and not advanced keywords such as product names | The amount of data for product, reviews and tweets per brand was not consistent | For ingredient harmfulness, the data is perfectly valid as it has scientific backing. Using tweet sentiment and review data however, may not be perfectly representative of reality | A customer may have repeated review based on multiple experience Sentiment analysis may be based on multiple tweets that could have been one | Entity, domain and referential integrities were considered with constraints |
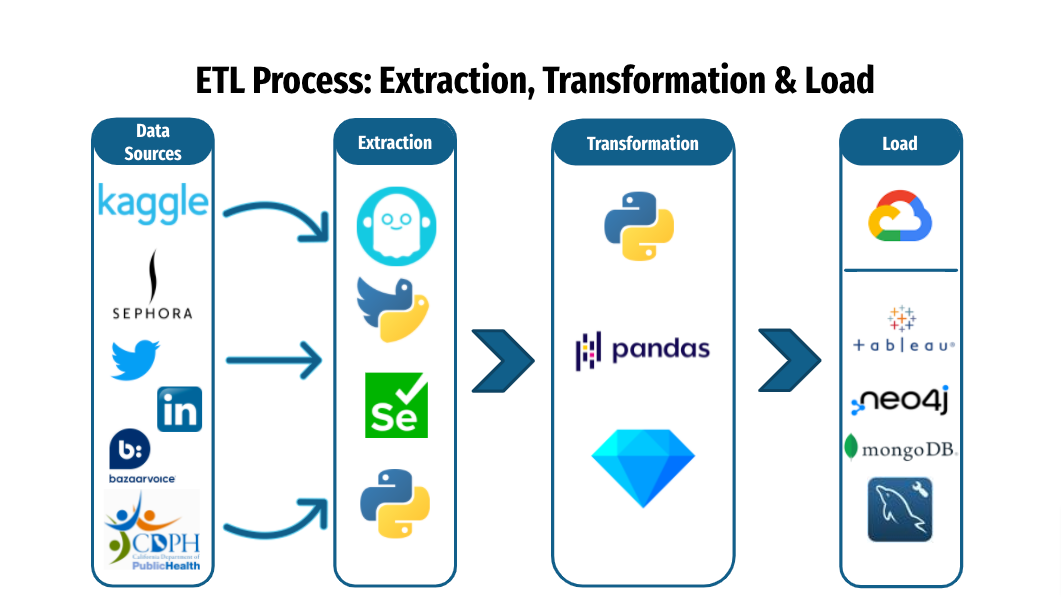
ETL Process: Extraction, Transformation & Load
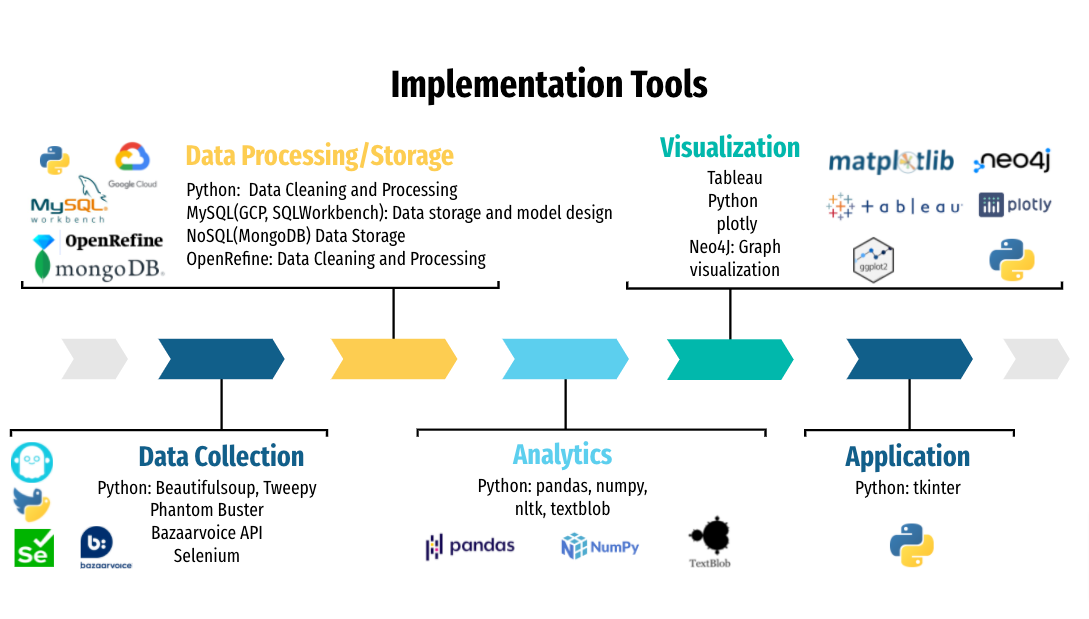
Implementation Tools
Design Consideraton
Branding Original product contains products across all categories, but we limit our data to facial brands under Sephora’s makeup and skincare categories.
Outliers & Anomalies Tweet location data contains non-location data. Intensive clustering and replacing with NULL if no-location can be derived from.
Ingredients Intermediary lookup table linking harmful ingredients to the product’ ingredient. Dealing With NAs MySQL Workbench recognizes NULL instead of empty string so removed unused columns and filled NaNs as NULL.
Product Reviews The reviews have too many attributes that are sparsely populated due to the difference between product categories, making it hard to create table columns in SQL for it.
Thus, using NoSQL and store as key value pairs is what we decided to do.
Data Naming Convention Standardize the format for names across entities and attributes (snake case).
Normalization Using brand id across the tables, referring to the brand table to normalize.